반응형
참고
-
컨테이너 및 파드 메모리 리소스 할당 - k8s Docs
-
[k8s] 파드의 우선순위(Pod QoS, Quality of Service) - 김징어의 Devlog
-
파드에 대한 서비스 품질(QoS) 구성 - k8s Docs
pod를 배포해봤다면 spec.container.resources는 흔하게 접할 수 있습니다.
사실 'pod가 배포되고 실행될 때 사용하는 리소스의 최소, 최대값을 정의한다' 정도로 간단한 것으로 알고 있었는데
spec.container.resources.requsts가 왜 필요하지? 라는 물음을 정리 하다가
빙산의 일각처럼 숨겨진 중요한 내용이 있어 같이 정리해봤습니다.
요약
-
묻지도 따지지도 말고
-
pod배포 시 모든 컨테이너에
-
반드시 request, limit을 정의해야 하며
-
중요도가 높은 pod라면 반드시 request, limit의 값을 동일하게 사용하자
728x90
Pod의 Resource 요청
pod 매니패스트
apiVersion: v1
kind: Pod
metadata:
name: demo
namespace: example
spec:
containers:
- name: demo-ctr
image: polinux/stress
resources:
requests:
cpu : 500m
memory: "100Mi"
limits:
cpu : "1"
memory: "200Mi"보통 pod 배포 시 위의 매니패스트 형태로 리소스를 할당합니다.
request에서 정의한 리소스만큼 여유가 있는 node에 pod가 할당되고 필요 시
limit에 정의된 만큼 pod의 리소스 사용량이 커진다는 것은 알고 있었는데요.
request에서 요청한 리소스 만큼 배포된 pod가 어떤 방식으로 limit까지 확장되는지 궁굼해졌습니다.
...
여기저기 이것저것 찾아봤는데...
심플하네요 -0-
만약 limit 정의 없이 request만 정의된 매니패스트가 배포 되면
spec:
containers:
- name: demo-ctr
image: polinux/stress
resources:
requests:
cpu : 500m
memory: "100Mi"cpu 500m, memory 100Mi 만큼 여유있는 node에 배포가 됩니다.
pod가 실행 되다가 cpu와 momory가 더 필요하면 request로 요청 했던 것 이상 node에 여유가 있는 만큼 덩치가 커집니다.
반대로 request 정의 없이 limit만 정의된 매니패스트가 배포되면
spec:
containers:
- name: demo-ctr
image: polinux/stress
resources:
limits:
cpu : "1"
memory: "200Mi"자동으로 request값은 limit값으로 채워지게 되어
cpu 1, memory 200Mi 만큼 여유있는 node에 배포가 됩니다.
음....
만약
-
node가 두 개가 있고
-
request만 정의된 pod가
-
1번 node에서 실행되다가 cpu나 memory가 부족해지면
-
덩치를 더 키우기 위해
-
2번노드로 옮겨가려고 할 수 있겠네
음.... limit은 꼭 걸어줘야겠네요
아니 잠깐 그럼 request가 왜 필요하지? 왜?
음.....
아무리 생각해도 request는 쓸모가 없는 것 같습니다.
앞으로 pod 정의할 때 limit만 걸고 써도 충분할 것 같네요
request가 쓸모없다고 계속 생각이 들어서
request로 인해 이슈가 되는 사례가 있는지 검색을 해봤는데 아래와 같은 내용이 있었습니다.
cpu사용량은 limit에 도달 하더라도 throttling이 걸리기 때문에 지연시간이 생길 뿐 pod가 못쓰는 상태가 되지 않지만,
memory는 limit에 도달하면 OOM(Out Of Memory)출력과 함께 pod가 종료 됩니다.
cpu 부족으로 인한 스케줄링 되지 못하고 pending 상태
Events:
Reason Message
------ -------
FailedScheduling No nodes are available that match all of the following predicates:: Insufficient cpu (3).memory부족으로 pod가 종료된 상태
lastState:
terminated:
containerID: 65183c1877aaec2e8427bc95609cc52677a454b56fcb24340dbd22917c23b10f
exitCode: 137
finishedAt: 2017-06-20T20:52:19Z
reason: OOMKilled
startedAt: null그리고 OOM을 덜 만나고 싶으면 request와 limit을 동일하게 요청 하는것이 효과가 있다. 라는글귀도 있었습니다.
도대체 request는 왜 만들어 놓은 것인지 진짜 쓸모가 없는 것인지 또 검색해 봅니다.
...
오우 저런... QoS...
QoS (Quality of Service)
QoS... 이건 또 뭐죠...
아... k8s진짜 뭐 양파 껍질마냥 까도까도 계속 뭔가 나오네.. 환장하겄네요
일단... Go! ㅠㅠ
QoS 종류
k8s는 pod를 생성할 때 다음 세 가지 QoS 클래스 중 하나를 할당한다고 합니다. (무슨 뜻인지 번역기의 도움을...)
-
Guaranteed : 보장
-
Burstable : 파열 가능
-
BestEffort : 최고의 노력
ㅋㅋㅋㅋㅋㅋ 무슨 말일까요 ㅜㅜ
QoS 조건
k8s Docs의 문서에서 설명하는 QoS 클래스 조건을 추출 해 봤습니다.
|
|
할당 조건
|
|
Guaranteed
|
- 파드 내 모든 컨테이너는 메모리 상한과 메모리 요청량을 가지고 있어야 한다.
- 파드 내 모든 컨테이너의 메모리 상한이 메모리 요청량과 일치해야 한다.
- 파드 내 모든 컨테이너는 CPU 상한과 CPU 요청량을 가지고 있어야 한다.
- 파드 내 모든 컨테이너의 CPU 상한이 CPU 요청량과 일치해야 한다.
|
|
Burstable
|
- 파드가 Guaranteed QoS 클래스의 기준을 만족하지 않는다.
- 파드 내에서 최소한 하나의 컨테이너가 메모리 또는 CPU 요청량/상한을 가진다.
|
|
BestEffort
|
- 파드의 컨테이너에 메모리 또는 cpu의 상한이나 요청이 없어야 한다
|
압축해 봅시다.
-
Guranteed : pod의 모든 컨테이너가 cpu, memory가 정의되어 있고, request와 limit의 값이 동일하다.
-
BestEffort : pod의 모든 컨테이너가 requst와 limit이 정의되어 있지 않다.
-
Burstable : 그 외
일단 어떤 조건일 때 어떤 QoS가 할당되는지는 정리가 되었고, QoS 클래스가 다르면 어떤 차이가 있는지 확인해봐야겠죠
QoS 의미
k8s에서는 리소스가 부족할 때 우선순위가 낮은 pod를 강제로 종료 시킵니다.
우선순위가 낮은 pod색출할 때 PriorityClass와 함께 QoS도 영향을 준다고 합니다.
(또 나왔어.... PriorityClass...)
QoS 클래스 세 가지의 우선순위
-
Guaranteed : 높은 우선순위
-
Burstable : 중간
-
BestEffort : 낮은 우선순위
cluster에 리소스가 부족하게 되면
우선순위가 가장 낮은 pod가 먼저 종료 대상이 되는데요
일반적으로 BestEffort로 할당 된 pod가 먼저 종료 되고, 그 다음은 Burstable가 대상입니다.
(pod를 제거해야될 상황이 되면 pod마다 점수를 매겨서 선정을 하게 되는데... 이건 또 다른 연구 대상이라 제외하고 넘어가겠습니다. ㅠㅠ)
그 다음으로 대상은 Guaranteed이지만, 위 둘과는 다르게 cluster에 memory가 부족한 경우에만 후보에 오른다고 합니다.
추가로 cluster에 Guaranteed로 배포된 pod만 존재하는 경우 OOM Score가 높은 pod가 먼저 제거 된다고 합니다.
(사용중인 memory percentage가 높은 pod가 1순위 제거대상)
-
OOM Score = 사용중인 메모리/Request 메모리
이쯤되니 pod 매니패스트에 resource 정의는 진짜 필수라고 다시한번 느껴지고
윗 쪽에서 requst없이 limit만 배포하려 했었는데.. ;; (k8s가 별 희안한걸 만들어놔서...)
반드시 request와 limit 모두 같은 값으로 정의하고 사용하도록 해야 겠습니다.
이래저래 발에 체이기만 하는 request는 없어져도 좋을 것 같다는 생각을 해봅니다.
반응형
끝으로
istio 로 pod의 cpu 사용량을 모니터링 했던적이 있었는데
grafana에 표기되는 cpu 사용량이 100%를 넘는 경우가 있어 이상하게 여겼던 기억이 있습니다.
request와 limit을 살펴보고 나니 왠지 사용량 계산 때 request만큼을 max로 계산하여
pod에 부하를 주니까 limit까지 사용량이 늘어나서 cpu 사용량이 100%를 넘었던것이 아니였을까 생각해 봅니다.
cluster에 배포된 pod하나 잡아서 적용된 QoS를 확인해 봅니다.
대상은 coredns
kubectl get pod -n kube-system
dscribe pod로 확인
kubectl describe pod coredns-dc97c5f55-4hwsn -n kube-system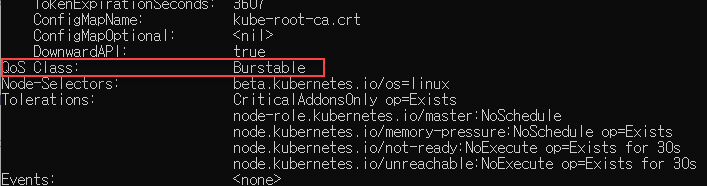
get pod로 확인
kubectl get pod coredns-dc97c5f55-4hwsn -n kube-system --output=yaml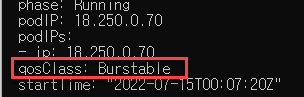
반응형
LIST
'IT > Kubernetes' 카테고리의 다른 글
| K8S Horizontal Pod Autoscaler (HPA) (0) | 2023.04.17 |
|---|---|
| K8S Autoscale 리서치 (0) | 2023.04.17 |
| Loki 설치 (0) | 2023.04.13 |
| prometheus 설치 (with pvc) (0) | 2023.04.13 |
| prometheus 설치 (with out pvc) (0) | 2023.04.13 |

